👩🏻💻 Point of Today I LEARNED
📌 SQL
● 코드카타 (61~65번 복습, 137번)
📌 Python
● 실무에 쓰는 머신러닝 기초 2~4강(다항회귀까지)
● standard 라이브세션 3회차 복습 (스케일링, 로그변환, KNN)
● ADsP 1주차 (데이터 개요)
머신러닝 프로세스 중
전처리와 모델링 (회귀 모델)에 대해 학습한 하루였다.
어쩌다보니 머신러닝 강의랑 라이브세션 강의 내용이 비슷해서
개념을 좀 더 확실히 이해할 수 있었다.
내일은 회귀와 예측 라이브세션이 있어서
한 번 더 복습할 수 있을 듯 !
개념 복습 완벽하게 하고,
실습에서 바로바로 활용할 수 있도록 미리 연습해놔야겠다.

1. SQL
1-1. 코드카타 제한시간 두고 풀기
1) 코드카타 137번
방법1. row_number
select
city, length(city)
from
(select
city,
row_number() over(order by length(city), city) min,
row_number() over(order by length(city) desc, city) max
from station) a
where
min = 1
or max = 1
방법2. union
(select
city, length(city)
from station
order by 2, 1
limit 1)
UNION
(select
city, length(city)
from station
order by 2 desc, 1
limit 1)2. Python
2-1. 실무에 쓰는 머신러닝 기초 2~4강
머신러닝 프로세스
데이터 수집 ▶ 전처리 ▶ 모델링 ▶ 성능평가 ▶ 최적화 ▶ 배포
raw data에서 불필요하거나 노이즈 있는 부분을 처리하여 분석 목적에 맞게 가공하는 과정
① 결측치
- 삭제
- 대체 (평균,중앙값/최빈값/직전후값/groupby값/예측모델 등)
② 이상치
- 탐지기법 : Z-score(정규분포 조건, ±3) / IQR / Isolation Forest / DBscan
③ 스케일링 (정규화/표준화)
- 서로 다른 범위(스케일)을 동등 범위로 대치
- ☞ 동등하게 비교 가능
- ☞ 머신러닝 학습시 데이터 편향성 제거
- ☞ 이상치 처리시 정확도 증가
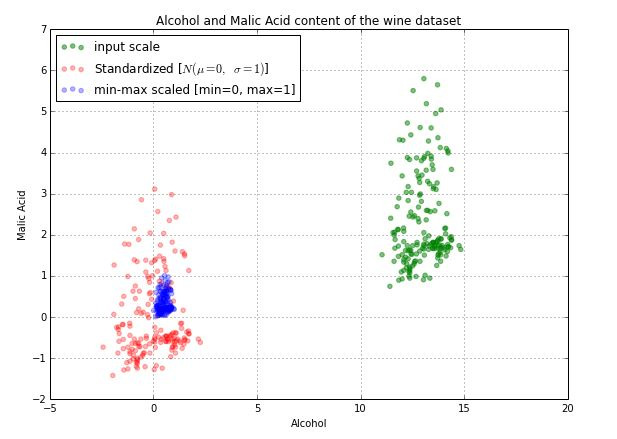
정규화 (MinMaxScaler)
- 최소값 0, 최대값 1로 지정해서 모든 수를 [0~1] 사이로 매핑
- 컬럼들의 차이에 대한 비율을 유지한 상태로 변환
- 최소값, 최대값이 이상치에 민감 (= 이상치 있으면 대부분 데이터가 한쪽에 치우침) ☞ 반드시 이상치 처리하고 정규화
- 새로운 최소값, 최대값이 입력되면 재학습 필요
- 활용 알고리즘
- KNN(K-최근접 이웃)
- 신경망 (Neural Networks)
from sklearn.preprocessing import MinMaxScaler
minmax_scaler = MinMaxScaler()
minmax_scaler.fit_transform(df['컬럼명']) # 결과값은 배열 형태
# fit: 열에서 최소값,최대값 찾는다.
# transform : 찾은 최소값,최대값으로 데이터들을 0~1 범위로 변환한다.
표준화
- 평균 0, 표준편차 1로 재구성
- Z값이 -∞ ~ +∞ 범위에 있지만, 대부분 ±3 이내에 포함됨. (나머지는 이상치)
- 데이터가 정규분포였을 경우 표준정규분포
- 데이터가 정규분포가 아니었을 경우 (ex. 긴꼬리분포) 로그변환, RobustScaler 등의 추가 작업 필요
- 원본 데이터 분포가 그대로 유지되기 때문에 이상치에 영향을 받지 않지만, 이상치 처리 후 표준화하는 게 바람직
- 활용 알고리즘
- KNN(K-최근접 이웃)
- K-Means 클러스터링(PCA)
- SVM (서포트 벡터 머신)
- 로지스틱 회귀 / 선형 회귀
from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler()
standard_scaler.fit_transform(df['컬럼명']) # 결과값은 배열 형태
④ 불균형 데이터 처리
- 극도로 적은 클래스에 대해서는 예측하지 못할 가능성 발생 (데이터 편향문제)
- 해결 방법
- Random Oversampling : 소수 클래스를 단순 복제해서 개수 늘림
- SMOTE (Synthetic Minority Over-sampling Technique) : 소수 클래스의 데이터들의 특성을 조합한 새로운 가상 데이터 생성 (아래 코드)
- Undersampling : 다수 클래스 개수 줄이기
- 혼합 기법 :SMOTE + Undersampling ...
from imblearn.over_sampling import SMOTE
smote = SMOTE()
X_res, Y_res = smote.fit_resample(X,Y)
⑤ 범주형 데이터 변환
One-Hot Encoding
- 범주형 데이터일 때
- 범주에 해당하면 1, 아니면 0 으로 변환
- 예시) 부산 = [1,0,0,0], 대전 = [0,1,0,0], 대구 = [0,0,1,0], 광주 = [0,0,0,1]
- 범주 많을수록 컬럼 많아져서 복잡
- 머신러닝할 때 숫자 크기로 서열 정보 오해석 가능성 X
pd.get_dummies(df, coulmns= ['변환할 컬럼'] , drop_first= True)
Label Encoding
- 순서형 데이터일 때
- 범주를 숫자로 매핑
- 예시) 1등급 = 1, 2등급 = 2, 3등급 = 1 / 사이즈 's' = 1, 'm' = 2, 'l' = 3)
- 숫자 크기로 서열 정보 오해석 가능성 높음
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
df['컬럼명'] = encoder.fit_transform(df['변환할컬럼'])
⑥ 피처 엔지니어링
모델 성능 향상을 위해 기존 데이터를 변형/ 새로운 조합으로 새로운 특성을 만드는 작업
- 파생변수 생성
- 변수 선택 (다중 공선성 block) (←차원 축소랑 다른 개념)
- 상관관계 확인 후 높으면 제거
- 분산 팽창 계수(VIF) 계산해서 높은 계수 가진 변수 제거
- VIF : 어떤 변수 하나가 다른 변수들과 얼마나 관련되어 있는지 수치로 보여주는 지표
- 모델 기반 중요도 : 트리기반모델 (random forest, XGBoost 등) 훈련 후 중요도 낮은 변수 제거
머신러닝 프로세스
데이터 수집 ▶ 전처리 ▶ 모델링 ▶ 성능평가 ▶ 최적화 ▶ 배포
독립변수(X)와 종속변수(Y)의 관계를 추정하여,
1) 종속변수의 변화값을 예측하고
2) 각 독립변수의 영향력 크기를 파악하는
통계/머신러닝(지도학습) 기법
① 선형회귀
- 독립변수(X)와 종속변수(Y)가 선형적 관계를 맺고 있다고 가정 (일차방정식)
- 학습과정
- 회귀계수 초기화
- 손실함수 설정 (주로 MSE(Mean Squared Error) 사용)
- 최적화하면서 회귀계수 업데이트
- 수학적 방법
- 경사하강법
- 학습을 반복하면서 가장 오차가 적은 계수와 절편을 찾는 방법
- 데이터 크기 클수록 권장
- 학습 및 예측
- 코드 1 (수학적 방법)
# 1. 독립,종속변수 분리
X = df.data
Y = df.target
# 2. 학습/검증 데이터 분리
X_train, X_test, Y_train, Y_test = train_test_split(
X,Y,
test_size=0.2, # 20%는 test 데이터로, 80%는 train 데이터로 쓰겠다.
random_state=42 # 재현성을 높이기 위해 랜덤 패턴을 고정시키겠다.
)
# 3. 학습데이터에 선형회귀 모델 적용
lin_reg = LinearRegression()
lin_reg.fit(X_train, Y_train)
# 4. 학습된 걸 바탕으로 Y값 새로 예측
y_pred_lin = lin_reg.predict(X_test)
# 5. 성능 측정
# 실제값과 예측값의 오차 계산
mse_lin = mean_squared_error(Y_test, y_pred_lin) # (정답값, 예측값) 순서 지키기
# 오차계산에 대한 점수 (0~1 사이의 값을 가지며 1에 가까울수록 잘했다는 의미)
r2_lin = r2_score(Y_test, y_pred_lin)
# 평균 비율 오차 (예측값이 실제값보다 높게 나오면 음수값 나옴)
def MPE(y_true, y_pred):
return np.mean((y_true - y_pred) / y_true) * 100
# 6. 확인
print("가중치(coefficient):", lin_reg.coef_) # .coef_
print("절편(intercept):", lin_reg.intercept_) # .intercept_
print("MSE:", mse_lin)
print("R2 점수:", r2_lin)
print("평균 비율 오차 : ", MPE(y_test, y_pred_lin))- 코드 2 (경사하강법)
# 3. 학습데이터에 SGDRegressor 모델 적용
sgd_reg = SGDRegressor(max_iter=6000, # 학습횟수 결정 (많이 할수록 오차가 적어지겠지만 너무 크지 않은 적당한 값을 넣어줘야함)
tol=1e-3, # 오차가 tol값보다 내려가면 학습 멈추도록 설정
random_state=42
)
sgd_reg.fit(X_train, y_train)
# 4. 학습된 걸 바탕으로 Y값 새로 예측
y_pred_sgd = sgd_reg.predict(X_test)
# 5. 성능 측정
# 실제값과 예측값의 오차 계산
mse_sgd = mean_squared_error(Y_test, y_pred_sgd)
# 오차계산에 대한 점수 (0~1 사이의 값을 가지며 1에 가까울수록 잘했다는 의미)
r2_sgd = r2_score(Y_test, y_pred_sgd)
# 평균 비율 오차 (예측값이 실제값보다 높게 나오면 음수값 나옴)
def MPE(y_true, y_pred):
return np.mean((y_true - y_pred) / y_true) * 100
# 6. 확인
print("가중치(coefficient):", sgd_reg.coef_)
print("절편(intercept):", sgd_reg.intercept_)
print("MSE:", mse_sgd)
print("R2 점수:", r2_sgd)
print("평균 비율 오차 : ", MPE(y_test, y_pred_sgd))
② 다항회귀
- 독립변수(X)와 종속변수(Y)를 비선형적 관계로 가정
- 선형회귀를 확장해서 독립변수의 차수를 높여 비선형 관계를 모델링
- 고차원일수록 복잡해지기 때문에 과적합 문제 - 일반화가 어려운 문제 발생
- 코드
# 파이프라인 사용해서 두 가지 처리를 한 번에
# 1. 학습 데이터에 다항회귀(2차) -> 선형회귀 모델 적용
poly_model = Pipeline([
('poly', PolynomialFeatures(degree=2, include_bias=False)),
('lin_reg', LinearRegression())
])
poly_model.fit(X_train, y_train)
# 2. 학습된 걸 바탕으로 Y값 새로 예측
y_pred_poly = poly_model.predict(X_test)
# 3. 성능 측정
mse_poly = mean_squared_error(y_test, y_pred_poly)
r2_score_poly = r2_score(y_test, y_pred_poly)
def MPE(y_true, y_pred):
return np.mean((y_true - y_pred) / y_true) * 100
# 4. 확인
print("MSE:", mse_poly)
print("R2:", r2_poly)
print("평균 비율 오차 : ", MPE(y_test, y_pred_poly))2) standard 라이브세션 3회차
핵심 개념 : 표준화, 정규화 / 로그변환 / KNN (지도학습-분류모델)
* 스케일링에 대한 부분은 위에서 통합해서 정리함.
① 로그 변환
- 데이터 분포가 정규분포를 이루지 않고, 한 쪽으로 치우쳐 있을 때 (히스토그램으로 파악)
- 큰 수를 작은 수로 변환하기 위해 사용
- np.log(df)
- x값이 커질수록 기울기 감소하는 로그함수 특성 활용



② KNN (K-최근접 이웃)
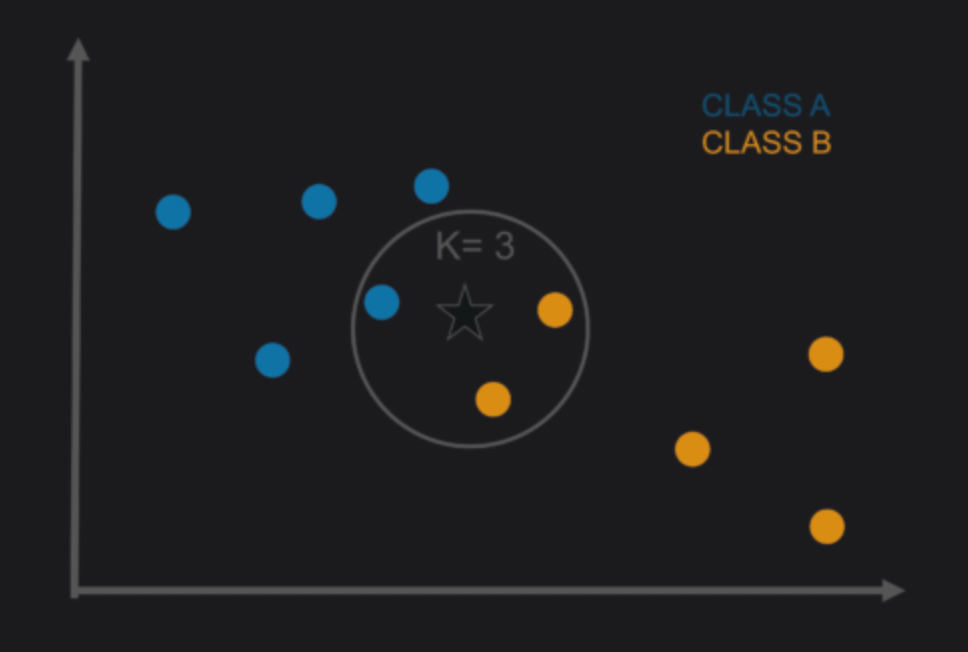
- 머신러닝 지도학습의 분류 알고리즘
- k값을 기준으로 근접한 데이터끼리 묶어서 분류 (거리 기반)
- 반드시 스케일링한 후 진행
- 거리 측정방식
- 유클리드 거리 : 가장 일반적, 절대 거리 측정
- 맨해튼 거리 : 2차원 평면 공간에서 두 점 사이의 거리를 측정하는 방법 중 하나로, 두 점 사이의 수평 및 수직 이동 거리의 합으로 정의
'데이터 분석' 카테고리의 다른 글
| [250410] 윈도우 함수에서의 group by, 재귀문, having, on절에 case when / 유형별 통계검증법, 상관계수 분류 (0) | 2025.04.10 |
|---|---|
| [250409] 로지스틱회귀, 선형회귀모델의 성능평가, 파이프라인 (0) | 2025.04.09 |
| [250407] 데이터타입별 검증법/상관계수, 회귀, 머신러닝 개요 (0) | 2025.04.07 |
| [day48] 분명 금요일인데 기쁘지가 않어. 주말이 없기 때문이야. (0) | 2025.04.04 |
| [day47] 하루가 너무 빨리 지나간다. 할 게 무진장 많기 때문이다. (0) | 2025.04.03 |