👩🏻💻 Point of Today I LEARNED
📌 선택학습반 (Product Data Science)
↗ 3회차
📌 API 활용 실습과제
↗ 네이버 검색어 트렌드 - 검색량 수집 및 line graph 시각화 실습
↗ 카카오맵 - 할리스 카페 위치 정보 파악 및 folium 시각화 실습 (위도/경도)
📌 웹 크롤링
↗ 정적 크롤링 - AI 기사 추출 실습
📌 최종 프로젝트 주제 탐색
1. Product Data Scientist
< 갑작스러운 지표 변동 이해하기 >
지표 변동의 원인을 파악하고 이에 대해 체계적으로 분석해야 한다.
1단계 변동의 심각성 판단
- 계절성이 있는 주기적인 변동인가?
- 데이터 로깅 방식의 변경 여부
- 제품/서비스 출시 여부
2단계 Funnel 분석으로 문제가 발생한 정확한 지점 식별
- ex) 문제 상황 : 갑자기 카카오톡 메시지 총 전송량이 급감했다.
- 퍼널
- 어플 실행
- 메시지 작성 인터페이스 (대화창)
- 메시지 전송 시도
- 메시지 전송 성공
- 퍼널
3단계 세그멘테이션에서 원인을 좀 더 구체화
→ 특정 그룹에게만 영향이 있었는지? 아니면 모든 사용자들이 같은 행동 양상을 띄는가?
→ 여러 가설을 세워서 파헤치기
- 기기 유형 : Android, iOS, Web, mWeb
- 앱 버전 : 최근 업데이트 여부
- 국가/지역
- 사용자 유형 : 신규/기존
4단계 해결 방안 도출 및 관계자와 커뮤니케이션
- 문제 해결을 위한 액셜 플랜 설계
- 제품 팀과 커뮤니케이션
- 단기적 조치 ~ 장기적 개선 방안 모색
2. API 강의 복습 및 과제
2-1. 네이버 검색 API를 활용한 검색량 조회
# 1. API 기본 URL
base_url = 'https://openapi.naver.com/v1/datalab/search'⬇︎
# 2. API 요청 헤더 설정
client_id = " "
client_secret = " "
headers = {
'X-Naver-Client-Id': client_id,
'X-Naver-Client-Secret': client_secret,
'Content-Type': 'application/json'
}⬇︎
# 3. API 요청 파라미터 설정
params = {
'startDate': '2024-05-01',
'endDate': '2025-04-30', # 지난 1년간의 데이터를
'timeUnit': 'week', # 주간단위로 가져옴
'keywordGroups': [
{
'groupName': '패션의류',
'keywords': ['지그재그', '무신사', '29cm']
},
{
'groupName': '전자제품',
'keywords': ['애플', '삼성', 'lg']
},
{
'groupName': '화장품뷰티',
'keywords': ['뷰티컬리', '올리브영', '시코르']
},
{
'groupName': '식품구매',
'keywords': ['마켓컬리', '쿠팡', '오아시스마켓']
}
]
}파라미터 설정
각 그룹별 대표하는 브랜드 3가지를 키워드로 지정해줬다.
파라미터 각 항목이 어떤 의미인지 헷갈려서 지피티에게 물어봄 . . .
keywordGroups ✅ 필수 여러 검색어 묶음을 비교하려고 만들 때 사용하는 배열 전체를 감싸는 큰 리스트 groupName ✅ 필수 해당 검색어 묶음의 대표 이름(라벨)
사용자가 구별하기 쉬우려고 임의로 만든 그룹제목"대선" keywords ✅ 필수 실제로 검색량을 조사할 구체적인 단어들 "후보", "단일화" 등
⬇︎
# 4. 응답 결과 저장
response = requests.post(base_url, headers=headers, json=params) # 네이버 검색어는 post 메서드를 사용
if response.status_code == 200:
result = response.json() # json 형식으로 파싱
for item in result['results']:
print(f'제목: {item['title']}')
print(f'검색어: {item['keywords']}')
for data in item['data']:
print(f" 기간: {data['period']}, 검색량 비율: {data['ratio']}")
print('-' * 50)
else:
print(f'Error Code: {response.status_code}')
print(f'Error Message: {response.text}')
응답결과목록 설정
⬇︎
# 응답 결과 저장
response = requests.post(base_url, headers=headers, json=params)
# 결과 처리 및 시각화
if response.status_code == 200:
result = response.json()
# 빈 DataFrame 만들기
df = pd.DataFrame()
# 각 그룹별로 데이터를 넣어주기
for item in result['results']:
group = item['title']
keyword = item['keywords']
temp_df = pd.DataFrame(item['data'])
temp_df['group'] = group
df = pd.concat([df, temp_df], ignore_index=True)
# 피벗 테이블로 시계열 형태로 변환 후 시각화
pivot_df = df.pivot(index='period', columns='group', values='ratio')
plt.figure(figsize=(14, 6))
plt.rc('font', family='AppleGothic')
for col in pivot_df.columns:
plt.plot(pivot_df.index, pivot_df[col], label=col)
plt.title('네이버 검색 트렌드 (주간, 그룹별)', fontsize=16)
plt.xlabel('기간', fontsize=12)
plt.ylabel('검색량 비율', fontsize=12)
plt.xticks(rotation=45)
plt.legend()
plt.tight_layout()
plt.grid(True)
plt.show()
else:
print(f'Error Code: {response.status_code}')
print(f'Error Message: {response.text}')
- '마켓컬리', '쿠팡', '오아시스마켓' 검색량이 압도적으로 많다.
- 사실 쿠팡이 식품만 판매하는 게 아니라서 keyword 설정을 잘못한 거 같기도 하다.
재밌어서 다른 키워드로 또 검색해봤다.
이번엔 배달 플랫폼으로. keyword는 그룹당 하나씩만.
params = {
'startDate': '2024-05-01',
'endDate': '2025-04-30',
'timeUnit': 'week',
'keywordGroups': [
{
'groupName': '배달의민족',
'keywords': ['배달의민족']
},
{
'groupName': '쿠팡이츠',
'keywords': ['쿠팡이츠']
},
{
'groupName': '요기요',
'keywords': ['요기요']
},
{
'groupName': '땡겨요',
'keywords': ['땡겨요']
}
]
}
- 오.. 예상했던대로 1년간 배민이 1등이고, 다음으로 쿠팡이츠 > 요기요 > 땡겨요 순으로 검색량이 많다.
- 2025년 3월 24일 주간에 딱 한 번 쿠팡이츠 검색량이 배민을 이겼다.
- 찾아보니 3월 25일에 쿠팡이츠에서 포장수수료 관련한 정책을 내놓음.
- 요기요는.. 2024년 5월~8월까지 검색량 들쭉달쭉하다가 결국 하향 후 그대로 유지 중. 심지어 땡겨요에 역전당하기도 함.
2-2. 카카오맵 API를 활용한 할리스 카페 위도/경도 구하기
# 0. 할리스 카페 기본 정보 들어있는 csv 파일 불러오기 (주소정보 필수)
df = pd.read_csv('/Users/t2024-m0164/Desktop/Data/6. API : 웹 크롤링 실습/1. 데이터 수집 API 실습 파일/hollys_stores.csv')⬇︎
# 1. API 기본 URL
url = "https://dapi.kakao.com/v2/local/search/keyword.json"⬇︎
# 2. 헤더 정보 입력
headers = {"Authorization": 'KakaoAK {REST_API_KEY}'}카카오맵 인증 설정은 네이버랑 달랐다.
Authorization 을 사용함
* 발급받은 api key를 입력해서 실행시켰더니
{'errorType': 'NotAuthorizedError', 'message': 'App(Data) disabled OPEN_MAP_AND_LOCAL service.'} # '앱은 존재하지만 해당 API 기능은 꺼져 있어서 접근할 수 없다' 는 의미이런 에러가 났다.
카카오맵의 로컬 API 사용 권한을 활성화해줘야 하는 문제였다.
[ 해결 방법 ]
1. https://developers.kakao.com 접속
2. 내 애플리케이션
3. 등록한 애플리케이션 클릭
4. 좌측 메뉴에서 '설정 > 앱 권한신청 > 앱 권한'
5. 카카오맵 선택 후 체크박스 활성화 ON
⬇︎
# 3. 위도/경도 저장할 열 준비
df['위도'] = None
df['경도'] = None⬇︎
# 4. 반복문으로 주소 변환 요청
for i, row in df.iterrows():
query = row['address']
try:
res = requests.get(url,
headers=headers,
params={'query': query})
if res.status_code == 200:
result = res.json()
if result['documents']:
doc = result['documents'][0]
df.at[i, '위도'] = doc['y']
df.at[i, '경도'] = doc['x']
else:
print(f"[결과 없음] {query}")
else:
print(f"[오류] status: {res.status_code}, 주소: {query}")
time.sleep(2) # 너무 빠르면 차단당할 수 있음
except Exception as e:
print(f"[예외 발생] {query} → {e}")
# 5. csv 파일로 저장
df.to_csv('할리스매장_위경도.csv', index=False, encoding='utf-8-sig')
print("✅ 변환 완료! 파일 저장됨.")
원래 phone 컬럼까지만 있었는데 위도, 경도가 추가됨.
⬇︎
# 6. 최종 시각화
import pandas as pd
import folium
# 1) CSV 파일 불러오기
df = pd.read_csv('할리스매장_위경도.csv')
# 2) 중심 좌표 계산 (평균값 또는 특정 지역 중심)
center_lat = df['위도'].astype(float).mean()
center_lon = df['경도'].astype(float).mean()
# 3) 지도 객체 생성
map_hollys = folium.Map(location=[center_lat, center_lon], zoom_start=12)
# 4) 각 매장 마커 추가
for i, row in df.iterrows():
try:
folium.Marker(
location=[float(row['위도']), float(row['경도'])],
popup=f"{row['name']}<br>{row['address']}",
icon=folium.Icon(color='red', icon='coffee', prefix='fa')
).add_to(map_hollys)
except:
continue # 좌표 없는 경우 생략
# 5) 지도 저장
map_hollys.save('hollys_map.html')
print("✅ hollys_map.html 파일로 저장 완료!")
3. 웹 크롤링
3-1. 정적 크롤링
1) HTML 파싱 기초

<html>
<body>
<div class="container">
<h1 id="title">웹 크롤링 기초 학습하기</h1>
<p class="content">BeautifulSoup을 이용한 HTML 파싱 방법을 배워봅시다.</p>
<p class="content">CSS 선택자를 활용하면 원하는 요소를 쉽게 찾을 수 있습니다.</p>
<ul class="items">
<li class="item">HTML 구조 이해하기</li>
<li class="item second">CSS 선택자 활용하기</li>
<li class="item">데이터 추출 및 저장하기</li>
</ul>
<a href="https://example.com">더 알아보기</a>
</div>
</body>
</html>

🔸 간단 실습 🔸

두 개 모두 클래스가 content인 태그 조회하는 코드
** select는 클래스로 조회할 때 앞에 . 붙여야 함 (id로 조회할 땐 #)
2) AI타임즈 뉴스 수집 실습 과제
import requests
from bs4 import BeautifulSoup
import pandas as pd
import json
from typing import List, Dict⬇︎
# 1. 웹페이지 요청
def get_news_list(page: int) -> str:
url = "https://www.aitimes.com/news/articleList.html?view_type=sm"
params = {"page": page}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0'
}
try:
response = requests.get(url, params=params, headers=headers)
response.raise_for_status() # 오류가 있으면 예외를 발생시킴
return response.text
except requests.exceptions.RequestException as e:
print(f"페이지 {page} 요청 중 에러 발생: {e}")
return ""
# 테스트: 첫 페이지 가져오기
html = get_news_list(1)
print("HTML 일부:", html[:500]) # 처음 500자만 출력⬇︎
# 2. HTML 파싱
def parse_news_info(html: str) -> List[Dict]:
news_list = []
soup = BeautifulSoup(html, 'html.parser')
articles = soup.select('ul.type2 > li')
if not articles:
return news_list
for li in articles:
title_tag = li.select_one('h4.titles')
summary_tag = li.select_one('p.lead.line-6x2')
byline_tags = li.select('span.byline > em')
link_tag = li.select_one('a[href]')
if not (title_tag and summary_tag and len(byline_tags) >= 2 and link_tag):
continue
news = {
'제목': title_tag.get_text(strip=True),
'요약': summary_tag.get_text(strip=True),
'기자': byline_tags[0].get_text(strip=True),
'날짜': byline_tags[1].get_text(strip=True),
'링크': 'https://www.aitimes.com' + link_tag['href']
}
news_list.append(news)
return news_list
# 테스트: 첫 페이지 파싱하기
news_list = parse_news_info(html)
print(f"첫 페이지에서 찾은 뉴스 수: {len(news_list)}")
print("\n첫 번째 뉴스 정보:")
print(json.dumps(news_list[0], ensure_ascii=False, indent=2))⬇︎
# 3. 데이터 저장
def save_to_files(news_list: List[Dict], base_path: str = "/Users/t2024-m0164/Desktop/"):
"""
매장 정보를 CSV와 JSON 파일로 저장하는 함수
"""
# DataFrame 생성
df = pd.DataFrame(news_list)
# CSV 파일로 저장
csv_path = f"{base_path}news_list.csv"
df.to_csv(csv_path, encoding='utf-8', index=False)
# JSON 파일로 저장 (DataFrame 활용)
json_path = f"{base_path}news_list.json"
df.to_json(json_path, orient='records', force_ascii=False, indent=4)
print(f"CSV 파일 저장 완료: {csv_path}")
print(f"JSON 파일 저장 완료: {json_path}")
# 데이터 미리보기
print("\n데이터 미리보기:")
print(df.head())
# 테스트: 첫 페이지 데이터 저장하기
save_to_files(news_list)⬇︎
# 4. 전체 반복 (페이지 별로)
def main():
news_list = []
# 매장 정보 수집
print("AI 뉴스정보 수집 중...")
for page in range(1, 5): # 1~4 페이지만 수집 (테스트용)
html = get_news_list(page)
if html:
page_news = parse_news_info(html)
news_list.extend(page_news)
# stores += page_stores
print(f"페이지 {page}: {len(page_news)}개의 뉴스 정보 수집 완료")
if not news_list:
print("뉴스 정보를 가져오는데 실패했습니다.")
return
print(f"\n총 {len(news_list)}개의 뉴스 정보를 수집했습니다.")
# 데이터 저장
try:
save_to_files(news_list)
except Exception as e:
print(f"데이터 저장 중 에러 발생: {e}")
# 전체 과정 실행
main()
여기까지 크롤링 완료...
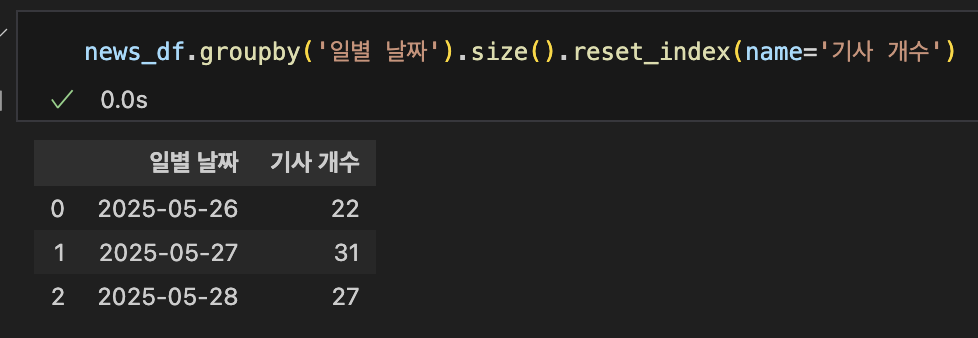
csv 파일 불러온 후 날짜 컬럼을 datetime으로 형변환해준 후 dt.day로 YYYY-MM-DD 형식의 컬럼을 다시 만들어줬다.
이후 일별 기사 개수 카운팅하는 것까지 분석해보았다.
'데이터 분석' 카테고리의 다른 글
| [250602] A/B 테스트 핵심요소 및 활용되는 통계적 개념, 최종 프로젝트 주제 선정 (0) | 2025.06.02 |
|---|---|
| [250530] 최종 프로젝트 시작 (0) | 2025.05.30 |
| [250527] 기회 규모 추정 프로세스, API 강의 복습 (1) | 2025.05.28 |
| [250526] Spark 1주차, Product Data Scientist 직무소개 (5) | 2025.05.27 |
| [250511] 실전 프로젝트, 5분 기록보드 시작 (0) | 2025.05.11 |