👩🏻💻 Point of Today I LEARNED
📌 최종 프로젝트
↗ 주제 탐색 및 선정
↗ 최종 기획안 제출
📌 선택학습반 (Product Data Science)
↗ 4회차

벌써 6월이다.
프로젝트 하나 끝나면 월이 달라져있는데 이게 맞나 ..
6월도 파이팅이다..!
1. Product Data Scientist
A/B 테스트
1) 핵심 요소
- 대조군 : 아무 변화를 주지 않은 그룹
- 실험군 : 효과가 궁금한 특정 업데이트를 적용한 그룹
- 평가지표 : 실험 효과를 측정할 수 있는 기준
- ex) CVR, CTR, 평균 구매 금액 등 ..
2) Randomization
- 실험군, 대조군은 반드시 랜덤화 (무작위 배정) 해야 한다.
- 두 그룹 간의 의도적인 차이가 없어야 하기 때문 (편향 제거)
- = 각 그룹의 학생들이 기본적으로 비슷한 특성을 가져야 하기 때문
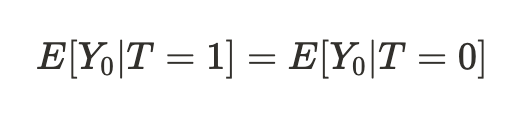
Y_0 : 실험 전의 결과
T : 실험 여부 (0은 대조군, 1은 실험군)
▶ 해석 : 실험 전에 대조군과 실험군의 평균 점수는 동일해야 한다
(출발선이 같아야 하기 때문)
▶ 평균이 완전히 같을 수는 없으니 이상하다 싶으면 분산으로 확인하기
3) 표준 오차 (Standard Error)
- 실험 결과의 정확도를 측정하기 위해 필요한 지표
- 샘플 평균이 모집단 평균에서 얼마나 벗어날 수 있는지 (이 실험 결과의 정확도, 신뢰도)를 측정
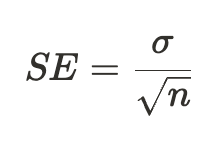
SE: 평균의 표준오차
σ : 모집단의 표준편차
n: 샘플 크기
▶ 해석 : 샘플이 적을수록 오차가 커짐
즉, 샘플 크기가 클수록 결과가 더 신뢰할만 하다.
→ 샘플 크기가 작으면 실험 결과가 우연일 가능성이 커지고, 이에 따라 변동성이 커지기 때문
그러나 우리는 보통 모집단의 표준편차를 알 수 없기 때문에
샘플 데이터를 활용해서 모집단의 SE를 추정해서 계산한다.
pandas의 .std() 함수 사용
'데이터 분석' 카테고리의 다른 글
| [250530] 최종 프로젝트 시작 (0) | 2025.05.30 |
|---|---|
| [250528] 지표 변동의 원인 파악 프로세스, API 실습, 정적 웹 크롤링 실습 (2) | 2025.05.28 |
| [250527] 기회 규모 추정 프로세스, API 강의 복습 (1) | 2025.05.28 |
| [250526] Spark 1주차, Product Data Scientist 직무소개 (5) | 2025.05.27 |
| [250511] 실전 프로젝트, 5분 기록보드 시작 (0) | 2025.05.11 |