👩🏻💻 Point of Today I LEARNED
📌 SQL
● 코드카타
📌 Python
● 실무에 쓰는 머신러닝 기초 7,8강 (군집/차원축소)
● 머신러닝 특강 복습 (군집/차원축소)
● 머신러닝 특강 어제 거 복습 (회귀)
심화 프로젝트 D-1
이제 지금까지 공부한 통계 + 머신러닝을 실전으로 써먹을 시간이다.
어떤 주제, 어떤 방법을 선택할지 기대가 된다.
많이 어렵고 머리 터지겠지만
후회없는 프로젝트가 될 수 있도록 해보자.

1. SQL
1-1. 코드카타 제한시간 두고 풀기
1) 코드카타 149번
https://www.hackerrank.com/challenges/the-pads/problem?isFullScreen=true
포인트. union all 을 쓰면 안 된다.
(select
concat(name,'(',left(occupation,1),')')
from occupations
order by name);
(select
concat('There are a total of ',count(1),' ',lower(occupation),'s.')
from occupations
group by occupation
order by count(1), occupation);
- 이유: 컬럼이 다르기 때문에
- 이럴 경우 그냥 쿼리 두 개를 써주기만 해도 된다.
2. Python
2-1. 실무에 쓰는 머신러닝 기초 7,8강 + 머신러닝 특강 복습(군집/차원축소)
1) 군집 분석 개념
- 비슷한 특성을 가진 데이터끼리 그룹핑 (군집/클러스터링) ➜ 각 그룹 내 데이터끼리의 유사도 최대화 & 다른 그룹과의 차이 최대화
- 군집에 쓸 컬럼은 주로 연속형(수치형) 변수 사용
- 이유 : 대부분의 군집 알고리즘은 유클리디안 거리 등의 거리기반 방식으로 비슷한 애들끼리 모으기 때문에 수치형일 때 정확하게 계산된다.
- 범주형 변수도 인코딩해서 수치화하면 가능하긴 하지만 범주 많을수록 고차원이 되어버리기 때문에 이럴 경우 차원축소를 해줘야 한다.
- 목적
- 데이터 구조 파악
- 세그먼트
- 마케팅 - 고객 세그먼트 / 제조업 - 기계 작동패턴 분류 등
- 절차
- 데이터 수집 및 기간 선정
- 최소 3개월 이상의 데이터셋 권장
- eda 및 전처리
- ① 이상치, 결측치 탐지 및 전부 제거 (혹은 DBScan으로 이상치 자연스럽게 분류)
- ✅ 결제금액처럼 유의미한 지표의 경우 이상치 제거 X
- ✅ 각 컬럼의 의미와 값에 대한 해석이 필요한 경우 주관 개입 필수 ex) 값이 0, 이진형 변수 등
- ② 스케일링
- ③ 상관관계 확인 (다중공선성 방지를 위해 한 쌍 중 하나만 가져오기)
- ④ 데이터 분포
- ⑤ unique 컬럼 제거 ex) customer_id
- ① 이상치, 결측치 탐지 및 전부 제거 (혹은 DBScan으로 이상치 자연스럽게 분류)
- 차원축소
- 군집 수 / 파라미터 설정
- 군집 수는 3~5개 정도로 시작해서 Silhouette Coefficient, elbow-point, Distance Map 참고해서 최적값 찾기
- 이 때, 초기 군집 수 참고할 수 있는 방법 (자세한 건 아래 참고)
- scree plot의 elbow-point
- Distance Map
- 군집 모델 적용 및 시각화(산점도로 분포 확인)
- 평가 및 결과 해석 ⭐️ ⭐️ ⭐️ ⭐️ ⭐️
- 비지도학습이기 때문에 정확한 평가가 쉽지 않기 때문에 실루엣 계수 등을 평가 지표로 활용
- 성능 평가 결과가 만족스럽지 않다면 다른 알고리즘 적용해보거나 파라미터 재조정, 피처 엔지니어링 등 계속 반복실험(매 실험마다 기록하는 게 중요)
- 하나의 군집이 전체의 절반 이상을 차지하면 다시 시작.. (클러스터 비중 편향 문제)
- 최종 결과가 나오면 각 군집이 갖는 주요 특징(평균값, 주요 변수 분포 등)을 파악해서 군집별 특징 정리
- 해석 기반 액션 아이템 제시
- 데이터 수집 및 기간 선정
- 매 실험 끝나고 확인해야 할 것들 ⭐️⭐️⭐️⭐️⭐️

✅ 초기 k값 설정 참고 방법
① scree plot 자료의 elbow-point
k값의 범위를 지정해서 각 k값으로 모델링 했을 때 걸리는 소요 시간을 계산해서 꺾은선 그래프로 보여주는 함수
from yellowbrick.cluster import KElbowVisualizer # KMeans 모델적용 model = KMeans() # k 값의 범위를 조정 가능 visualizer = KElbowVisualizer(model, k=(3,12)) # 데이터 적용 visualizer.fit(pca_df) visualizer.show()
② Distance Map
군집 간 거리를 시각화해줌 (어디까지나 확인용)from yellowbrick.cluster import intercluster_distance from sklearn.cluster import MiniBatchKMeans intercluster_distance(MiniBatchKMeans(5, random_state=42), pca_df)

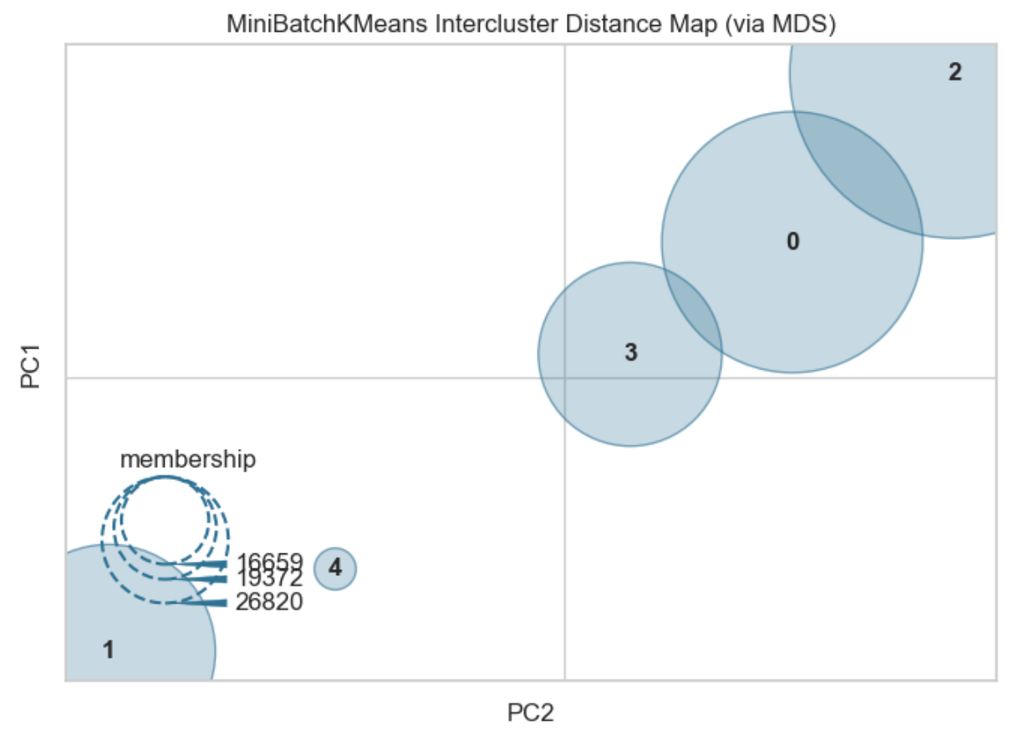
2) 군집 모델 종류
K-Means 클러스터링
- 각 군집(K)의 평균(Means)을 이용해서 클러스터링하는 모델
- 알고리즘 개요 ⭐️
- 인간이 K값 (군집 개수) 지정해주면
- 모델이 랜덤하게 K개의 중심점을 선택해서 모든 데이터 포인터들을 가장 가까운 중심에 할당시켜서 1차 클러스터링
- 중심점과 데이터포인터들 간의 거리를 최소화하기 위해 중심점을 재선택해서 클러스터링하는 과정을 반복
- 거리기반으로 최적의 중심점 K개 도출 (거리 평균이 더이상 바뀌지 않는 지점)
- 장점
- 계산 속도 빠르고 구현 간단
- 대용량 데이터에도 비교적 잘 작동
- 단점
- 군집 수를 몇 개 지정할지 최적값 찾는 게 중요
- 중심점에 영향을 미치는 이상치에 취약
- 원형 구조가 아닌 복잡한 형태의 분포는 적용이 어려움
DBScan
- 일정 거리(ε) 내 데이터가 많으면(최소 포인트 수 minPts 이상) 그 영역을 ‘밀도가 높다’고 판단해 군집화하는 기법
- 장점
- 이상치, 노이즈를 자연스럽게 하나의 군집처럼 파악 가능
- 밀도 기반이기 때문에 k값 불필요 (밀도 높으면 알아서 그룹핑함)
- 원형 구조가 아닌 복잡한 형태도 군집화 잘 함
- 단점
- 파라미터 ε, minPts 잘 해줘야 함
- 데이터 밀도 균일하지 않으면 성능 저하 (밀도기반 모델이니까.)
계층적 클러스터링(AgglomerativeClustering)
- 방법
- (확장형) 데이터 포인트 하나하나를 하나의 군집으로 시작해서 유사도 높은 애들끼리 병합 반복해서 최종적으로 군집 트리 형성
- (분리형) 하나의 거대 군집으로 시작해서 분할
- 장점
- 군집의 계층적 구조를 직관적으로 파악 가능 (by 덴드로그램 시각화)
- 군집 수를 명확하게 지정하지 않아도 덴드로그램의 특정 높이에 따라 유연하게 군집 개수 결정 가능
- 단점
- 계산이 복잡하기 때문에 대규모 데이터에 적용하기 어려움
3) 차원축소
- 중요한 변수 몇 개만 선택해서 재구성하는 기법
- 전처리 목적일 경우 반드시 모델 학습 전에 실행하기
- 장점
- 고차원일 경우의 복잡도 해결 (트리기반모델의 경우 고차원도 잘 처리하기 때문에 굳이 안해도 됨)
- 다중공선성 해결
- 노이즈 제거로 모델 성능 및 일반화 능력 개선
- 시각화 할 때 직관적인 결과 해석 가능
- 데이터 핵심 구조 및 패턴 발견 용이
PCA 주성분 분석

- 선형 축소
- 가장 분산이 큰 방향(= 각 군집별 대표적인 특성 정보를 담고있는 축) 상위 n개만 선별 추출하는 축소기법
- 주성분 = 데이터의 핵심적인 축 (not 컬럼!)
- 분산 크기에 따라 1주성분, 2주성분, ...
- 설명 분산 비율(explained_variance_ratio_)로 원하는 수준을 충족하는 적정 주성분 개수 확인 가능
- 예시) 2개 주성분만으로 전체 분산의 90%를 설명할 수 있다
- components_로 어떤 변수가 주성분에 얼마나 기여하는지 각각의 가중치 확인 가능 (= 해당 주성분이 어떤 피처들의 조합으로 형성되었는지 확인)
# 변수별 주성분에 대한 가중치
pd.DataFrame(pca.components_, columns=scale_df.columns, index=[pca_df.columns]).T
↪︎ 절대값 클수록 각 주성분에 대한 영향력이 크다는 것 (주성분의 대표 특성)
- 파라미터 n_components 사용법 (정수 2,3 권장)
- 정수 n ☞ '주성분 중 상위 n개만 사용할게' (← 주로 시각화 목적일 때 2 또는 3으로 사용)
- 실수 0.95 ☞ '전체 분산의 95%를 설명하는만큼 주성분 개수 선택해줘' (← 설명 분산 비율 적용해서 정확도 높이고 싶을 때 사용/ 시각화 어렵기 때문에 이 경우에는 주성분 중 일부만 시각화하거나 pairplot으로 구현하기)
- None (기본값) ☞ '일단 차원 축소하지 않고 모든 주성분 사용할게' (← fit() 이후 설명분산비율 보고 수동 조절 가능)
t-SNE, UMAP

- 비선형 축소 (고차원 데이터의 구조를 2D/3D로 매핑)
- 알고리즘 개요
- 고차원에서의 주변 데이터들 간의 거리를 바탕으로 지역적 확률 분포 계산
- 다른 차원에서도 '최대한' 같은 확률 분포로 배치 (경사하강법으로 최적화)
- 하이퍼파라미터 튜닝으로 성능 조절
- t-SNE perplexity, learning rate, iteration 수
- UMAP n_neighbors, min_dist 등
4) 군집 성능평가 지표
** 아래는 내부 평가에 해당하며, 더 확실한 평가를 위해서는 실제 확인 가능한 데이터와 군집결과를 비교하는 외부 평가 방법이 있다.
① 실루엣 계수 (Silhouette Score)
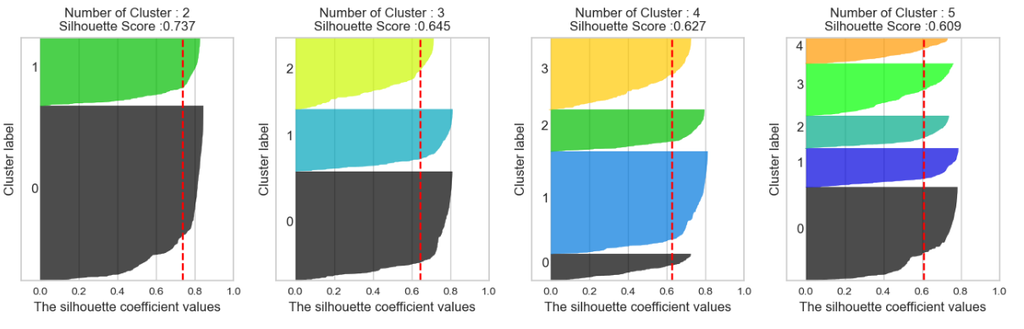

- 각 데이터 포인트의 응집도(a)와 분리도(b)를 이용해 계산
- 응집도(a) : 같은 군집 내 데이터와의 평균 거리 ☞ 낮을수록 좋음
- 분리도(b) : 가장 가까운 다른 군집과의 평균 거리 ☞ 높을수록 좋음
- -1~1 사이의 값
- 1에 가까울수록 군집 성능 좋음
- 0에 가까울수록 군집 경계
- 음수면 잘못된 군집화 의심
- 덩어리 쪼갤수록(k값 올라갈수록) 점수 낮아지는 건 당연함 ➜ 동일한 k값 기준으로 피처 조절해서 점수 비교
- sklearn.metrics.silhouette_samples
② Davies-Bouldin Index
- 군집 내 분산 & 군집 간 거리의 비율 ➜ 군집이 겹치는 문제에 대한 검사에 활용
- 0 이상의 값
- 0에 가까울수록 군집 성능 좋음
- 값이 커질수록 군집 품질 낮음
- 예시)
- DBScan 의 경우 노란색이랑 보라색 군집끼리 겹쳐짐
- (= 보라색 군집 내 분산이 크고, 보라색&노란색 군집 간 거리가 좁다)
- 이 경우 Davies-Bouldin Index 값이 커진다.

'데이터 분석' 카테고리의 다른 글
| [250507, 250508] 태블로, 대시보드 (0) | 2025.05.09 |
|---|---|
| [250501, 250502] 태블로 (0) | 2025.05.02 |
| [250416] 이상탐지, 회귀 (0) | 2025.04.16 |
| [250415] 알고리즘 선택가이드, 앙상블, 하이퍼파라미터 튜닝 (0) | 2025.04.15 |
| [250414] 통계적검증과 머신러닝 비교, 릿지/라쏘 회귀, 분류모델 성능평가, 다중분류 전체실습 (0) | 2025.04.14 |