👩🏻💻 Point of Today I LEARNED
📌 Python
● 머신러닝 특강 (분류)
● 실무에 쓰는 머신러닝 기초 5강 (앙상블)
튜터님이 그토록 강조하셨던 앙상블에 대해 집중적으로 공부했다.
두 개가 합쳐져서 앙상블이었구나.....
귀..엽..네.....

...................... ^ _ ^
2. Python
2-1. 머신러닝 특강 (분류)
전체적으로 어제 공부한 것을 복습하면서 중간중간 새로운 내용들이 보였다.
그런 것들은 어제 TIL에 추가해두었다.
알고리즘 선택 가이드
| 상황 | 추천 알고리즘 |
| 데이터가 적고 해석이 중요 | 로지스틱 회귀 |
| 단순히 비슷한 데이터로 분류하고 싶음 | KNN |
| 복잡한 경계 필요 | SVM / 트리기반 |
| 과적합 우려 | 랜덤 포레스트 |
| feature importance를 보고싶음 | 트리 기반 (랜덤 포레스트 등) |
| 성능 최우선 | 그래디언트 부스팅 (XGBoost, LightGBM) |
2-2. 실무에 쓰는 머신러닝 기초 5강 (앙상블)
1) 앙상블이란?
- 여러 개의 모델을 조합해서 하나의 모델을 사용했을 때보다 더 좋은 예측 성능을 내는 방법
- 목적
- 서로 다른 모델을 결합해서 오류 줄이려고
- 개별 모델의 편향/분산을 상호 보완 → 과적합 방지
- 종류
- 배깅 (Bagging)
- 학습 데이터를 무작위로 여러 샘플로 나누어 독립적으로 학습시키는 방법
- 여러 모델의 평균으로 결정→ 회귀 / 다수결로 결정 → 분류
- 랜덤 포레스트
- 장점
- 독립적으로 학습되기 때문에 병렬 처리 가능하고, 학습 속도 빠름
- 모델 간 상호 간섭이 적어서 안정적
- 과적합 방지
- 단점
- 메모리 사용이 비효율적
- 해석 어려움 → feature importance로 보완 가능
- 부스팅 (Boosting)
- 배깅 (Bagging)
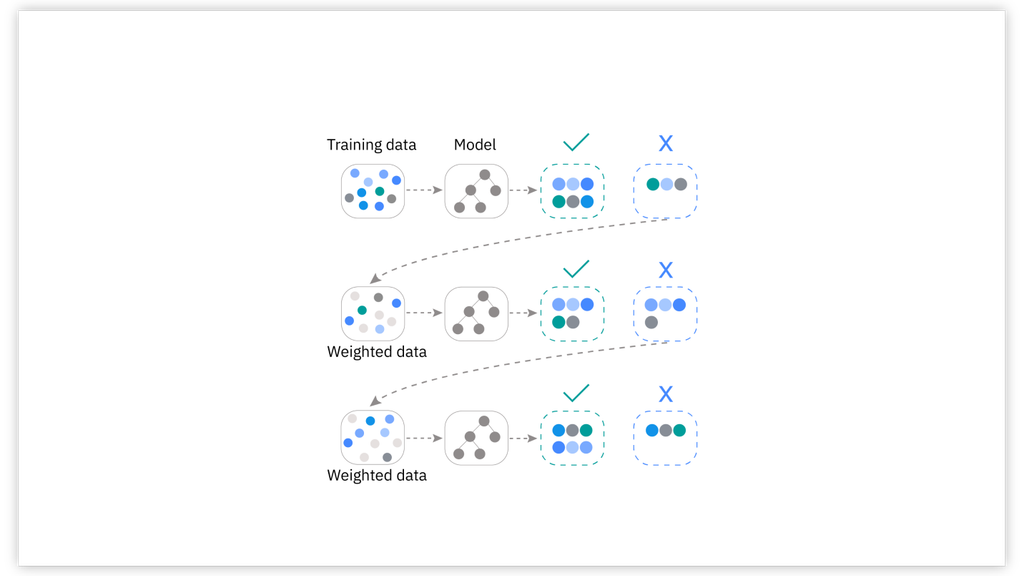
- 순차적으로 모델을 학습하면서 이전 모델이 만든 예측 오류를 보정하도록 설계 (경사하강법)
- 이전 모델의 틀린 부분에 가중치를 두면서 보완학습
- XGBoost (eXtreme Gradient Boosting), LightGBM, CatBoost
- 장점
- 높은 예측 정확도
- 복잡한 데이터도 잘 학습함
- 단점
- 병렬화가 쉽지 않아서 학습 속도 느림
- 하이퍼파라미터가 많고 튜닝이 까다로움
✅ 작동 예시(XGBoost) 간단 시나리오
1. 기본 모델(약한 결정 트리) 훈련 → 예측 오류 확인
2. 예측 오류가 컸던 샘플에 높은 가중치 부여
3. 다음 모델(결정 트리) 훈련 → 다시 오류 보정
4. 이 과정을 여러 번 반복하여, 최종 예측 시에는 모두 합산
2) 과적합, 과소적합
- 과적합 : 학습 데이터에 지나치게 특화되어서 일반화가 어려워짐에 따라 테스트 데이터에 대한 예측성능 떨어짐
- 원인
- 과도한 파라미터로 지나치게 복잡해짐
- 학습 데이터 수가 적어서 오히려 극소수의 사소한 것까지 민감하게 반응 (전체적인 경향성 파악을 못함)
- 해결 ⭐️
- 앙상블 모델 사용
- Regularization(규제) 적용 : penalty 적용 가능하면 L1, L2 규제 추가하기 or 릿지,랏쏘 회귀
- 드롭아웃 : 학습할 때 일부 뉴런을 확률적으로 비활성화해서 여러 모델 합친 효과 만들기 (딥러닝에서 주로 사용)
- 데이터 증강 : 이미지 데이터 회전/이동/반전, 자연어 데이터 유사한 패턴, 신호 데이터 가우시안 노이즈 추가 등
- 조기 종료 : 손실 증가하기 시작하면 학습 중단 ex) tol
- 원인
- 과소적합 : 너무 소량의 데이터로만 학습해서 패턴을 충분하게 학습하지 못해서 학습 데이터조차 맞추지 못함
- 해결
- 하이퍼파라미터로 튜닝 (모델 복잡도 증가)
- 더 오래 학습시키기
- 해결
3) 하이퍼 파라미터 튜닝
- 모델 학습 시작 전에 사람이 설정해야 하는 값
- n_estimators, max_dapth, max_iter, tol, random_state 등등
- 중요
- 데이터셋 나누기
- Training Set / Validation Set / Test Set
- 모델이 실제 테스트 데이터에 얼마나 일반화될 수 있는지 미리 평가해서 최적의 파라미터를 결정하는 데 필요한 중간점검용 데이터셋
- 특히, 하이퍼파라미터 튜닝에 대한 결과를 확인하기 위한 '검증/평가' 데이터로서 사용된다.
- + 과적합 여부 파악 + 조기 종료 기준으로 사용하기도 함
- 보통 test data의 절반을 validation data로 사용
- 교차 검증 (Cross Validation) ⭐️
- validation data 자체가 전체 데이터의 일부분에 불과하므로 정확한 검증이 어려울 수 있으니
- 전체 데이터를 여러 개의 폴드(Fold)로 나눠서 여러 번 학습 - 검증 반복해서 학습 성능의 평균을 냄
- K-Fold Cross Validation가 대표적인 교차검증 방식
- 데이터를 K개로 나눔 (보통 5 fold, 10 fold)
- 1개는 검증용, K-1개는 학습용으로 사용
- 이 과정을 K번 반복해서 매번 다른 폴드를 검증용으로 사용
- K개의 성능 평균으로 최종 모델의 성능을 평가
- 특히 데이터 수가 적을 때 많이 사용, 데이터 많을 경우에는 validation set 하나로 검증해도 괜찮
- 불균형 데이터의 경우 클래스 비율 유지한 채로 나눠야 함 (StartifiedKFold)
- 데이터셋 나누기
- 튜닝 방법 (내부적으로 자동으로 교차검증해서 최적 파라미터 탐색해줌)
- Grid Search
- 정의된 하이퍼파라미터의 모든 조합을 시도
- 장점 : 완전 탐색이므로 최적값 무조건 찾음
- 단점 : 파라미터 많을수록 연산량 급격히 증가
- ➜ 파라미터 범위 좁고, 후보 적을 때 사용
- Randomized Search
- 랜덤하게 하이퍼파라미터를 조합해서 일정 횟수만 시도
- 장점 : 다양한 영역을 빠르게 탐색 -> 속도 빠름
- 단점 : 완벽한 최적값 정확하게 못 찾을 수 있음
- ➜ 파라미터 범위 넓고, 후보 많을 때 사용
- 베이지안 최적화(Bayesian Optimization)
- 과거의 탐색 결과를 바탕으로 가장 유망한 하이퍼파라미터 범위를 중점적으로 탐색
- 장점 : 탐색 시간이 더 짧고 효율적
- 단점 : 구현 복잡도가 높음
- Grid Search
✅ 실습 순서 정리
1. Training Set / Validation Set / Test Set 분리 (교차검증 시에는 train,test만 사용)
2. 하이퍼파라미터 튜닝 및 교차검증(Grid Search, Randomized Search,베이지안 최적화 등)
3. 최적의 파라미터 도출해서 train data에 적용, 학습시키기
4. 학습된 모델로 test data 최종 성능 평가
- 실습
# catboost + gridsearch 실습
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from catboost import CatBoostClassifier
from sklearn.metrics import accuracy_score, classification_report
# 1. 데이터 로드
iris = load_iris()
X = iris.data
y = iris.target
# 2. 학습/테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=42,
stratify=y
)
# 3. 모델 적용
cat = CatBoostClassifier(verbose=0)
# 4. 그리드서치할 하이퍼파라미터 후보군 나열
param_grid3 = {
'iterations': [100, 300],
'learning_rate': [0.05, 0.1],
'depth': [4, 6],
'l2_leaf_reg': [1, 3]
}
# 5. 그리드 서치 수행
grid_cat = GridSearchCV(
estimator=cat, # 모델
param_grid=param_grid3, # 파라미터 후보군들
cv=3, # train data 몇 등분할지 결정 (k값)
scoring='accuracy',
n_jobs=-1)
grid_cat.fit(X_train, y_train)
# 6. 그리드 서치 통해서 얻은 최적의 파라미터 조합으로 학습시킨 후 테스트 데이터에 적용
best_model1 = grid_cat.best_estimator_
y_cat_pred = best_model1.predict(X_test)
# 7. test data 최종 성능 평가
print('최적의 파라미터 조합:', grid_cat.best_params_)
print('최적의 파라미터 조합으로 학습시켰을 때의 성능:', grid_cat.best_score_)
print('test data에 대한 최종 정확도:', accuracy_score(y_test, y_cat_pred))
print(confusion_matrix(y_test, y_cat_pred))
print(classification_report(y_test, y_cat_pred))⬇︎

Q. 최고 정확도랑 정확도가 동일하게 나왔다. 하이퍼파라미터 튜닝하고 나면 best_score_ 값이랑 그냥 accuracy_score은 항상 동일한 건가?
A. ❌
▶ best_score : 그리드서치 교차검증으로 얻은 파라미터 조합의 평균 정확도
(최적의 파라미터 조합을 썼을 때의 train data에 대한 성능 평가)
▶ accuracy_score : test data에 대한 모델의 예측 성능
(최종 test data의 성능 평가)
그럼 데이터 수가 적을 때는 두 개가 동일하게 나올 확률이 높군.
그래서 이 실습에서 두 개가 동일하게 나온거군.
4) 머신러닝 추가 개념
- 최적화 (Optimization)
- 하이퍼파라미터 튜닝 (그리드 서치, 랜덤서치, 베이지안 최적화 등)
- 피처 엔지니어링 (파생 변수 생성, 불필요한 변수 제거 등)
- 과적합 방지 (앙상블, 교차 검증, 규제 추가, 드롭아웃, 조기 종료 등)
- 배포 (Deployment)
- 학습 완료된 모델을 운영 환경에 배포
- 지속적인 모니터링해서 성능 개선
- MLOps (머신러닝 운영)
- Machine Learning + DevOps의 합성어
- 머신러닝 모델 개발부터 배포, 모니터링, 재학습, 롤백(Rollback) 등 전 과정을 자동화하고 효율적으로 운영하는 방법론
- 프로젝트 완성 → 실제 운영 단계에서 지속적인 모니터링과 데이터/모델 업데이트가 필요
5) 모델 해석 가능성 (Explainable AI, XAI)
- 결과의 이유(과정)를 설명하는 게 중요
- 주요 기법
- Feature Importance 시각화 (트리 기반 모델만 가능) ⭐️
- 전체 데이터에 대한 변수별 영향력의 크기를 알 수 있음
- like 선형모델의 회귀계수
- 개별 데이터마다 중요한 변수가 다를 수 있기 때문에 이럴 경우 아래 2가지 사용
- LIME(Local Interpretable Model-agnostic Explanations)
- SHAP(Shapley Additive Explanations)
- Feature Importance 시각화 (트리 기반 모델만 가능) ⭐️
'데이터 분석' 카테고리의 다른 글
| [250417] 군집, 차원축소 (0) | 2025.04.17 |
|---|---|
| [250416] 이상탐지, 회귀 (0) | 2025.04.16 |
| [250414] 통계적검증과 머신러닝 비교, 릿지/라쏘 회귀, 분류모델 성능평가, 다중분류 전체실습 (0) | 2025.04.14 |
| [250411] ⭐️ 분석 흐름 정리 ⭐️, 트리기반모델 (1) | 2025.04.11 |
| [250410] 윈도우 함수에서의 group by, 재귀문, having, on절에 case when / 유형별 통계검증법, 상관계수 분류 (0) | 2025.04.10 |