👩🏻💻 Point of Today I LEARNED
📌 SQL
● 코드카타
● QCC 4회차 복습
📌 Python
● 분석 흐름 정리
● standard 라이브세션 5회차
● 실무에 쓰는 머신러닝 기초 4강, 5강

할 말 없을 무
내 자신에게 화 많이 남
문제 풀 때 붕 떠있지 말고 차분해지자.
문제 똒빠로 읽짜 ... ㅈㅔ 발 !
1. SQL
1-1. 코드카타 제한시간 두고 풀기
1) 코드카타 145번
https://www.hackerrank.com/challenges/more-than-75-marks/problem?isFullScreen=true
select name
from students
where marks > 75
order by right(name,3), id- 처음에 substr(name,-1,3) 으로 풀었다가 틀렸다.
- 이유 : 제대로 하려면 substr(name,-3,3) 으로 해줘야 함
- right() 은 마지막 글자 n개를 가져와주므로 이거 써주는 게 안전.
1-2. QCC 4회차 복습
QCC 4회차
1번제출한 쿼리with filtered as ( select region_name from stores group by region_name having count(1) >= 2)select REGION_NAME, SALESfrom (select REGION_NAME, SALES, rank() over(partition by region_name order by sales desc) rnk from stores) awhere rnk
rosenps3.tistory.com
2. Python
2-1. 분석 흐름 및 사고 알고리즘 정리
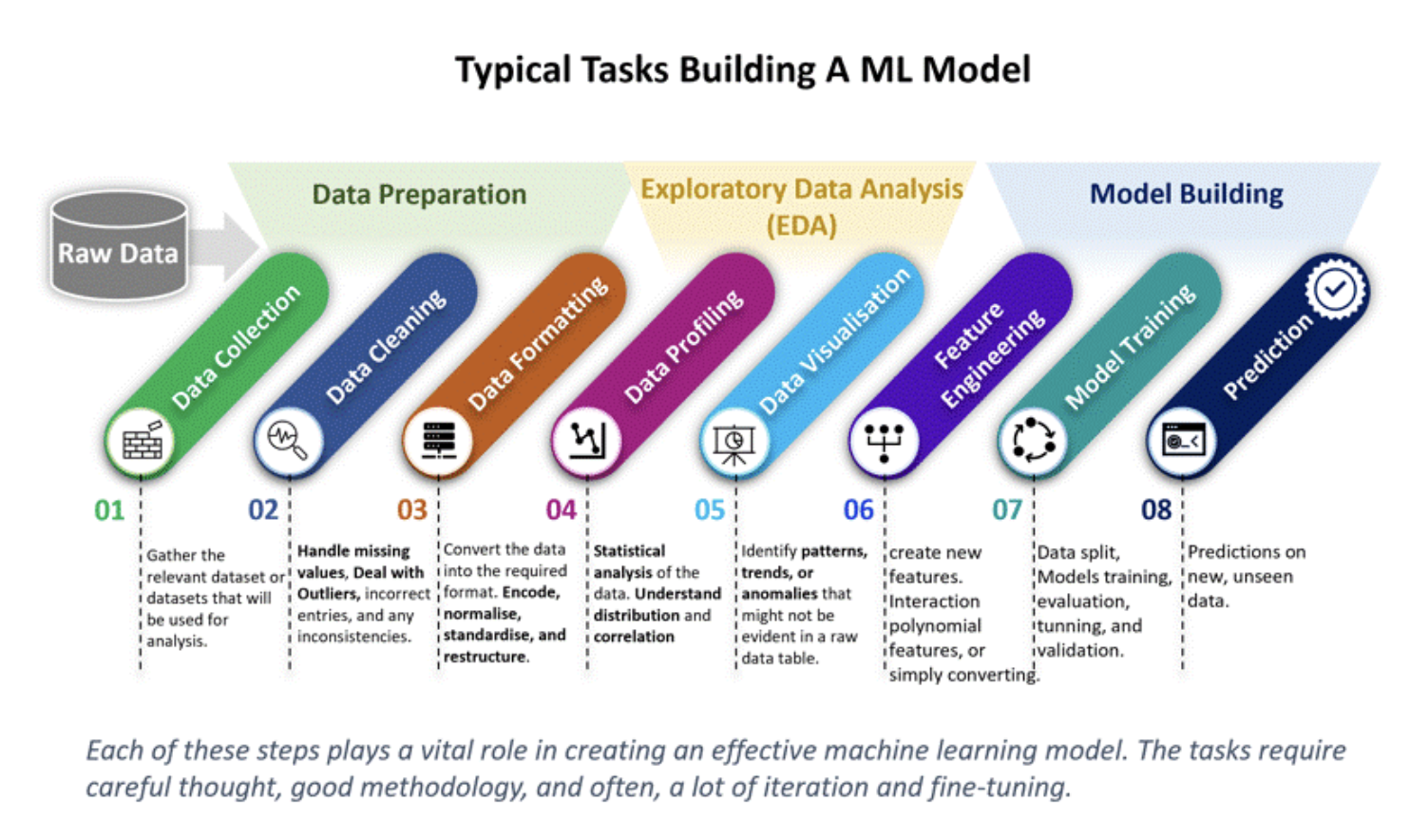
데이터 분석 프로세스
데이터 수집 ▶ EDA 및 전처리 ▶ 가설설정 ▶ 변수검증 및 관계 분석 ▶ 피처 엔지니어링 ▶ 머신러닝 ▶ 인사이트 도출 및 결론
⓪ 문제 정의 ⭐️
- 이 데이터 분석을 왜 하는가. 어떤 문제를 해결하려고 데이터 분석을 시작하는가.
- 즉, 데이터 분석의 목적을 가장 먼저 정의하기
- 예시) 목적 : 고객 이탈률 줄이기 -> 그럼 '어떤 요인'이 고객 이탈률에 영향을 미치는지 알아보자.
- 성공 기준 설정
- 예시) 실제 이탈 고객의 80% 이상을 정확히 예측 (재현율 기준)
① EDA 및 전처리
- 데이터 프레임 구조 파악 (.info() / .T) ☞ 이렇게 생겼군. 이런 컬럼들이 있군.
- 기초 통계 분석(평균, 분포, 범주별 특성 등) ☞ (.describe()) 평균&중위값 비교해서 이상치 탐지
- 시각화를 통한 데이터 이해
- 정규분포 여부 (히스토) ☞ 정규분포 아닌 거 같은데.. 정규성 검사해보자
- 이상치 탐지 (박스플롯) ☞ 이상치 확실히 있네. 정규성에 따라 Z-score/ IQR 확인하고 처리 방법 결정하자
- 변수 간 상관관계 파악 (히트맵/산점도) ☞ 가볍게 확인하는 정도로 보고, 너무 확연하게 상관관계 높으면 미리 제거
- 결측치/이상치 처리 ☞ 결측치가 대부분인 컬럼이거나 너무 명백하게 이상치인 경우만 제거
- 가설 설정을 하기 위한 패턴 및 관계 파악 (EDA 인사이트 정리 ⭐️)
② 가설설정
- EDA를 통해서 발견한 몇 가지 패턴/관계 중 유의미해보이는 것을 바탕으로 가설 설정
- 예시) 고객 만족도가 낮으면 이탈률이 높을 것이다.
③ 변수 검증 및 관계 분석
- 통계 검증
- 가설을 통계적으로 증명하기 (변수 간의 관계가 '있는지 없는지'와 그 값이 '통계적으로 유의미한지' 확인)
- 일단 독립성 가정하고 시작
- 데이터 타입과 데이터 분포의 정규성/등분산성 등을 파악한 후 가장 적합한 검증기법 적용
- 정규성 검정 : Shapiro-Wilk scipy.stats.shapiro() / QQ-plot statsmodels.graphics.qqplot()
- 등분산성 검정 : Levene's test levene()
- 정규성은 중심극한정리에 따라 반드시 충족해야 하는 건 아님
- z-test, t-test, ANOVA, 카이제곱 등
- 상관관계 확인
- 상관도를 정량적으로 측정 (변수 간 얼마나,어떻게 관련있는지 '관계의 크기 및 방향' 확인)
- 데이터 유형에 따라 다양한 방법이 있음
- pearson, spearman, Phi, Cramer's V 등
④ Feature Engineering
- 데이터 전처리의 연장선 (머신러닝 성능을 위한 재정교화)
- 머신러닝 모델 적용 전 변수 재구성
- 스케일링 (정규화/표준화) ☞ 반드시 이상치 처리한 후 스케일링하기 특히, 정규화!
- 로그 변환 ☞ 긴꼬리분포처럼 정규성 없을 경우, X값 커질수록 기울기 작아지는 특성 활용해서 큰 값을 작은 값으로 만들어주자.
- 범주형 인코딩 (One-Hot Encoding / Label Encoding) ☞ 범주형이야? → One-Hot Encoding, 순서형이야? → Label Encoding
- 불균형 데이터 처리 (SMOTE, ...)
- 유의미한 변수 활용해서 필요한 파생 변수 생성
- 다중공선성 재확인을 통해 최종 모델 학습 변수 선택 ☞ 앞에서 원핫인코딩 했거나 파생변수가 새로 생겨나면 다중공선성이 새로 생겼을 확률 높으니까 정확하게 변수 간 관계 확인해보자. (by 상관계수/VIF계산/모델기반 중요도 등)
- 모델 성능에 큰 영향을 줌
- 스케일링 관련 참고사항
- 거리기반 연산(KNN, PCA)과 경사하강법(로지스틱회귀, 선형 회귀, 신경망 등) 사용할 경우 스케일링 필수
- 트리 기반 모델(랜덤 포레스트, XGBoost, CatBoost 등)은 상대적인 크기가 중요하기 때문에 스케일링 불필요
⑤ 머신러닝 모델 적용
- 통계검증과 상관계수 확인을 통해 검증된 변수 및 feature engineering으로 새로 구성된 변수를 가지고 머신러닝 실행
- 지도학습- 분류/회귀 , 비지도학습- 군집/차원축소, 강화학습
- 결과 확인 (성능 평가⭐️)
- 회귀
- 선형회귀모델의 경우 ols.summary() 확인
- 잔차 플롯 그려서 패턴 랜덤한지 확인
- R2, MSE, MAE 등 손실함수 확인
- 분류
- accuracy, precision, recall, f1-score
- 혼동행렬
- rou-auc score 등
- 군집
- 차원축소
- 회귀
- 최적화 (모델 개선)
- 과적합/과소적합 확인
- 하이퍼파라미터 튜닝 (교차검증)
- 앙상블 적용
- feature importance 분석 및 시각화
- 가중치 조절 (규제)
- 변수 선택 및 추가 피처 엔지니어링 진행
⑥ 최종 모델 선택 및 결과 정리
- 가장 최적화된 모델 선택
- 최종 성능 지표 정리
⑦ 인사이트 도출 및 결론
- 통계적 추론을 통해 가설 검증을 하고, 머신러닝을 통해 값을 예측 및 분류하는 단계까지 가보면서 얻은 결과/인사이트를 토대로 앞서 정의한 문제를 해결하기 위해 어떤 전략을 취하면 좋을지 연결시키기
2-2. standard 라이브세션 5회차
1) 트리기반 모델이란?
- 의사결정나무 (Decision Tree)
- 질문을 던지면서 데이터를 나누는 구조
- 스무고개 느낌
- 해석력은 좋지만 예측 정확도가 좋지 않아서 잘 사용하지 않음
- 의사결정나무에 앙상블 기법 많이 사용
- 여러 나무를 합쳐서 더 강한 모델을 만드는 방법 (평균 - 회귀 / 다수결 - 분류)
- 기본 의사결정 나무의 예측 정확도를 개선
- 랜덤 포레스트, XGBoost, CatBoost 등
- 아래 고려사항들이 대부분 충족된다.
✅ 머신러닝 모델 고를 때 고려하는 것들
1. 예측 정확도
2. 학습 속도 / 예측 속도
3. 과적합 방지 능력 (앙상블)
4. 결측치 처리 가능 여부
5. 범주형 데이터 처리 능력 (CatBoost)
2) XGBoost (eXtreme Gradient Boosting)
- 특징
- 빠르고 정확 !
- 정형 데이터(표)에 강력
- 과적합 방지 기능 (앙상블인 것 자체만으로 과적합 방지되지만 추가적으로 reg_alpha, reg_lambda 사용해서 규제 적용도 가능)
- 결측치 자동 처리해줌
- feature importance 확인 가능
3) CatBoost
- 특징
- 범주형 데이터 인코딩 없이 바로 사용 가능
- 하이퍼파라미터 튜닝 없이도 성능 좋음
- 결측치 자동 처리해줌
- feature importance 확인 가능
4) 주요 하이퍼 파라미터
- 공통 ⭐️
| 파라미터 | 의미 | 추천 범위 | 비고 |
| n_estimators | 트리개수 | 100~1000 | - 과적합 방지를 위해 트리 개수를 너무 높게 잡으면 안됨 - train data만 많은 건 아무 의미 없음 - 랜덤포레스트에도 있음 |
| learning_rate | 학습률 | 0.01 ~ 0.3 | - 클수록 빠르게 수렴 - 적정수준이어야 함 (그리드서치 이용) |
| max_depth | 트리의 최대 깊이 | 3 ~ 10 | -깊어질수록 관점이 다양해지고 성능 올라가지만, 너무 깊어지면 과적합 문제 발생 - 랜덤포레스트에도 있음 |
- XGBoost
| 파라미터 | 의미 | 추천 범위 | 비고 |
| subsample | 각 트리마다 사용할 샘플 비율 | 0.5~1.0 | |
| colsample_bytree | 각 트리마다 사용할 컬럼 비율 | 0.5~1.0 | |
| gamma | 정보 획득이 얼마 이상일 때 split | 0~5 | |
| reg_alpha | L1 규제 | 0~1 | - 1에 가까울수록 강력한 규제 - 과적합 방지 |
| reg_lambda | L2 규제 | 0~1 | - 1에 가까울수록 강력한 규제 - 과적합 방지 |
- CatBoost
| 파라미터 | 의미 | 추천 범위 | 비고 |
| bagging_temperature | 랜덤성 조절 | 0~1 | |
| random_strength | 컬럼 선택 랜덤성 (비율) | 0~10 |
'데이터 분석' 카테고리의 다른 글
| [250415] 알고리즘 선택가이드, 앙상블, 하이퍼파라미터 튜닝 (0) | 2025.04.15 |
|---|---|
| [250414] 통계적검증과 머신러닝 비교, 릿지/라쏘 회귀, 분류모델 성능평가, 다중분류 전체실습 (0) | 2025.04.14 |
| [250410] 윈도우 함수에서의 group by, 재귀문, having, on절에 case when / 유형별 통계검증법, 상관계수 분류 (0) | 2025.04.10 |
| [250409] 로지스틱회귀, 선형회귀모델의 성능평가, 파이프라인 (0) | 2025.04.09 |
| [250408] 머신러닝 - 데이터 전처리, 모델링(회귀) (0) | 2025.04.08 |